AI Safety and Security
Despite the remarkable advancement of deep learning (DL) techniques in the past decade, certain inherent shortcomings and vulnerabilities persist, undermining the performance of these models in critical situations. First and foremost, DL models are prone to systematic failures when handling subsets of data involving unusual cases, out-of-distribution samples, and complex scenarios. Secondly, they are vulnerable under carefully-crafted malicious inputs, such as adversarial examples, where minuscule perturbations can mislead deep neural networks into making erroneous predictions. These flaws and susceptibilities raise serious concerns regarding the deployment of deep neural networks in domains where safety is paramount, e.g., autonomous driving and medical systems.
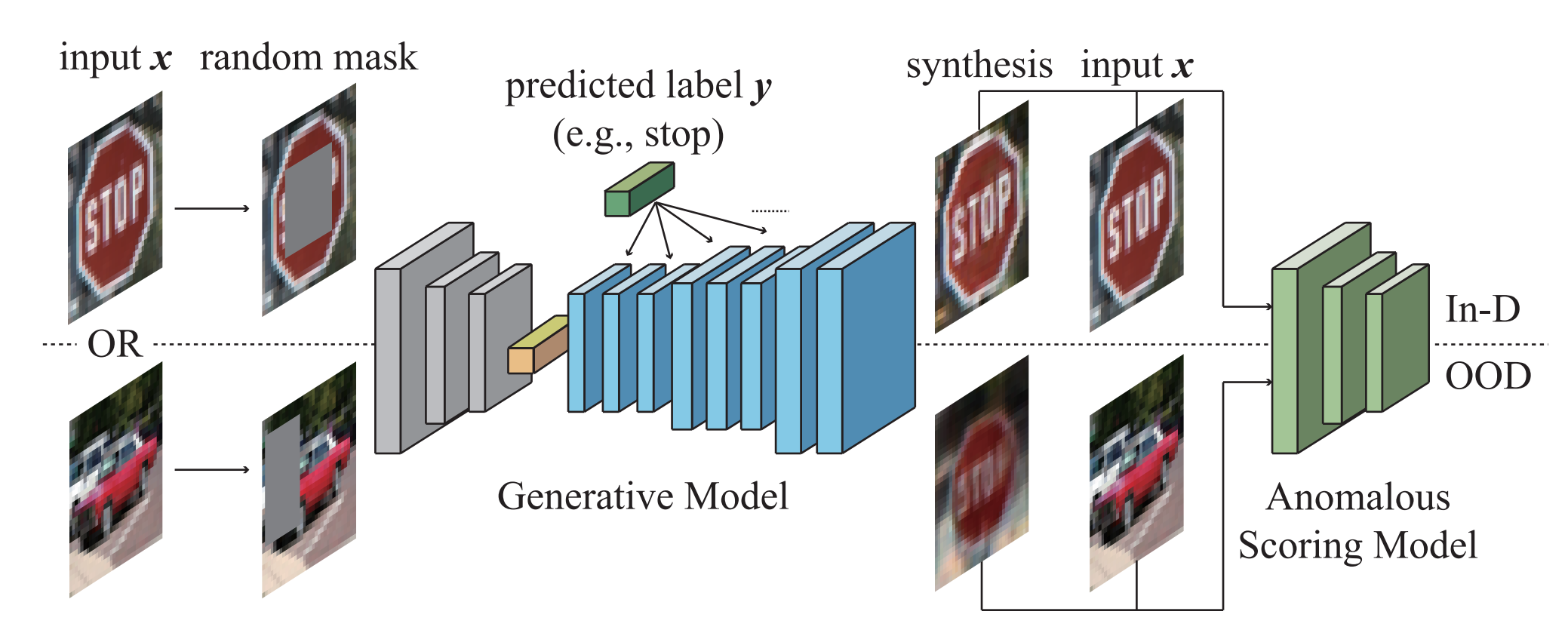
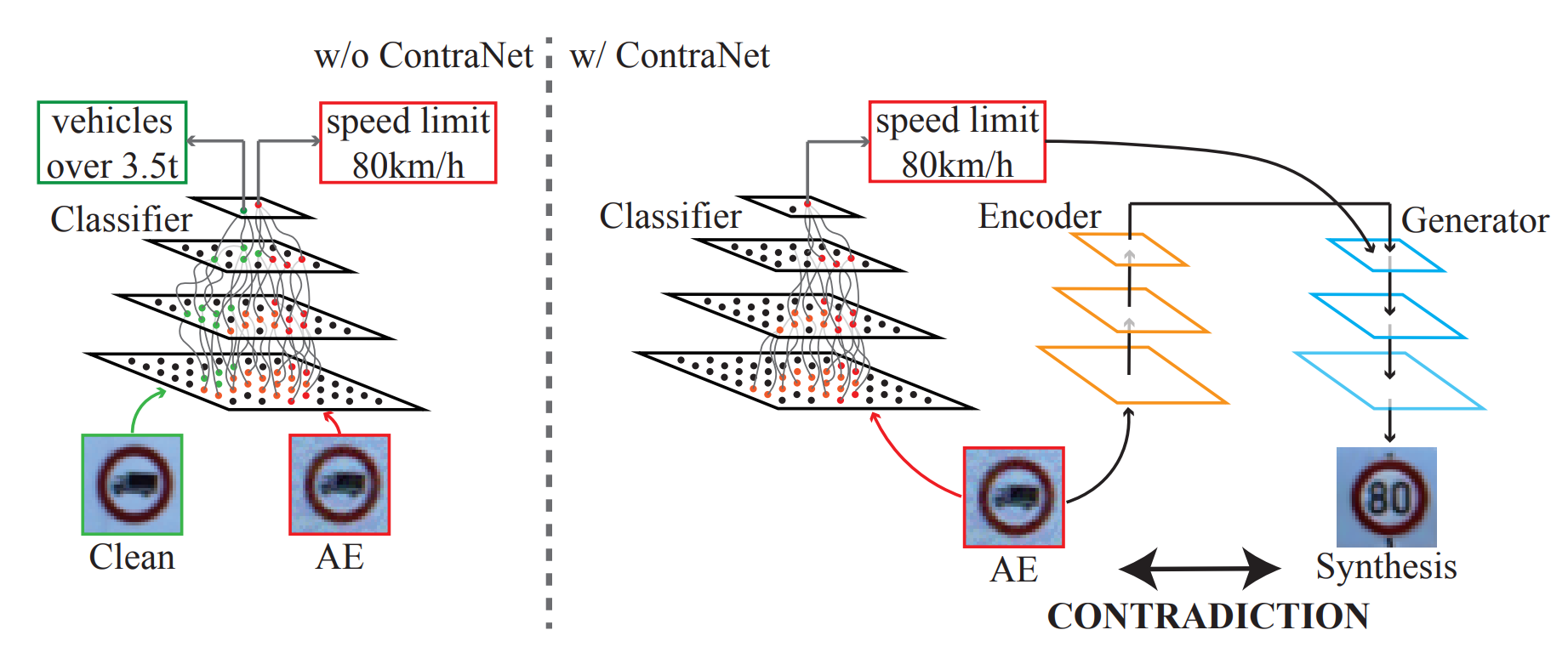
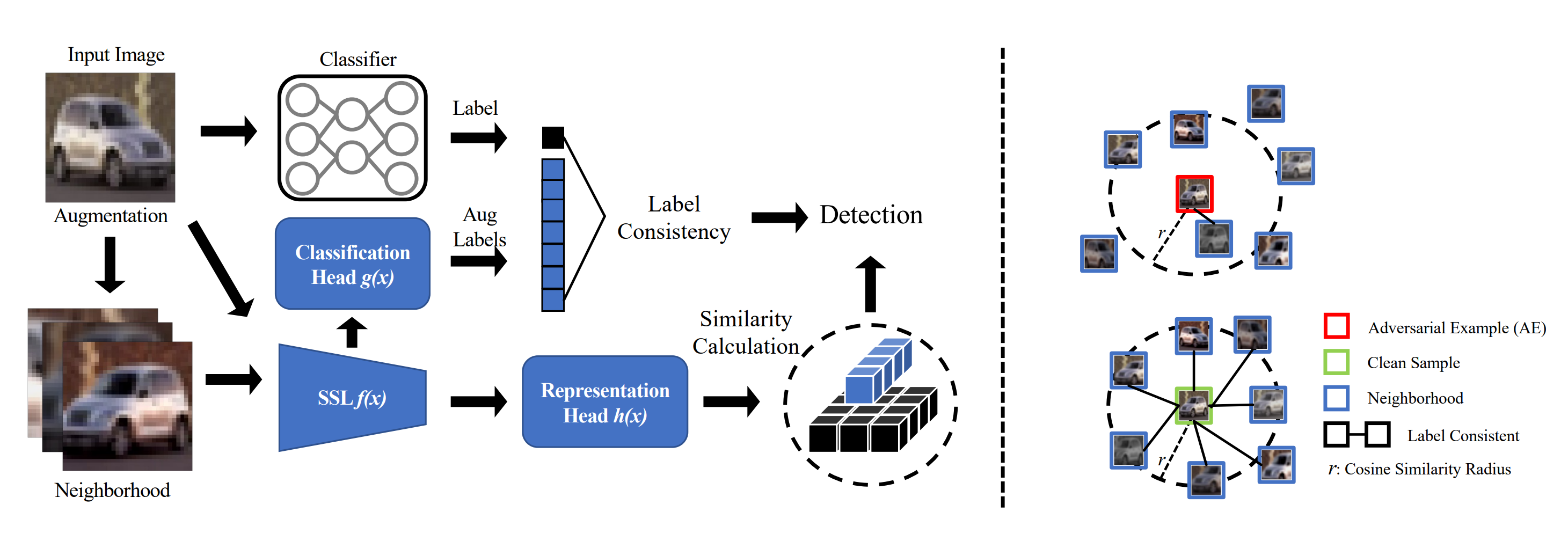
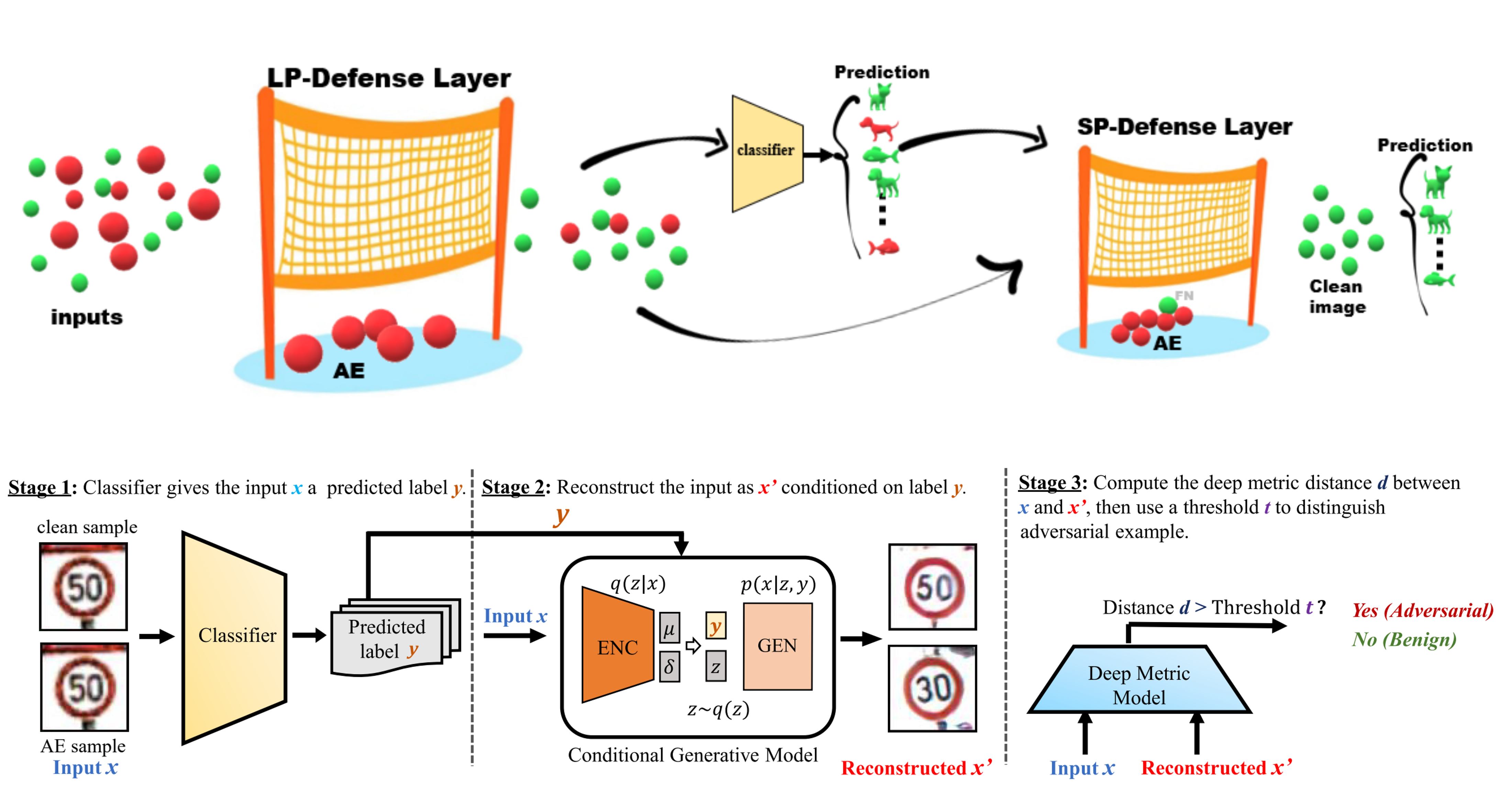
We introduce a collection of defense frameworks designed to safeguard deep neural networks from the risks outlined previously, applicable across a variety of tasks. Our strategies fundamentally use the outputs from deep neural networks as feedback, and incorporate the principle of semantic input validation with generative models to detect adversarial examples and out-of-distribution samples. In more detail, we conduct this input validation by supplying both the input and the predictions to a generative model, such as a Generative Adversarial Network or Stable Diffusion. This generates a synthetic output, which we then compare to the original input. For legitimate inputs that are correctly inferred, the synthetic output attempts to reconstruct the input. On the contrary, for AEs or OODs, instead of reconstructing the input, the synthetic output would be created to conform to the wrong predictions whenever possible. Consequently, by validating the distance between the input and the synthetic output, we can distinguish AEs or OODs from legitimate inputs.
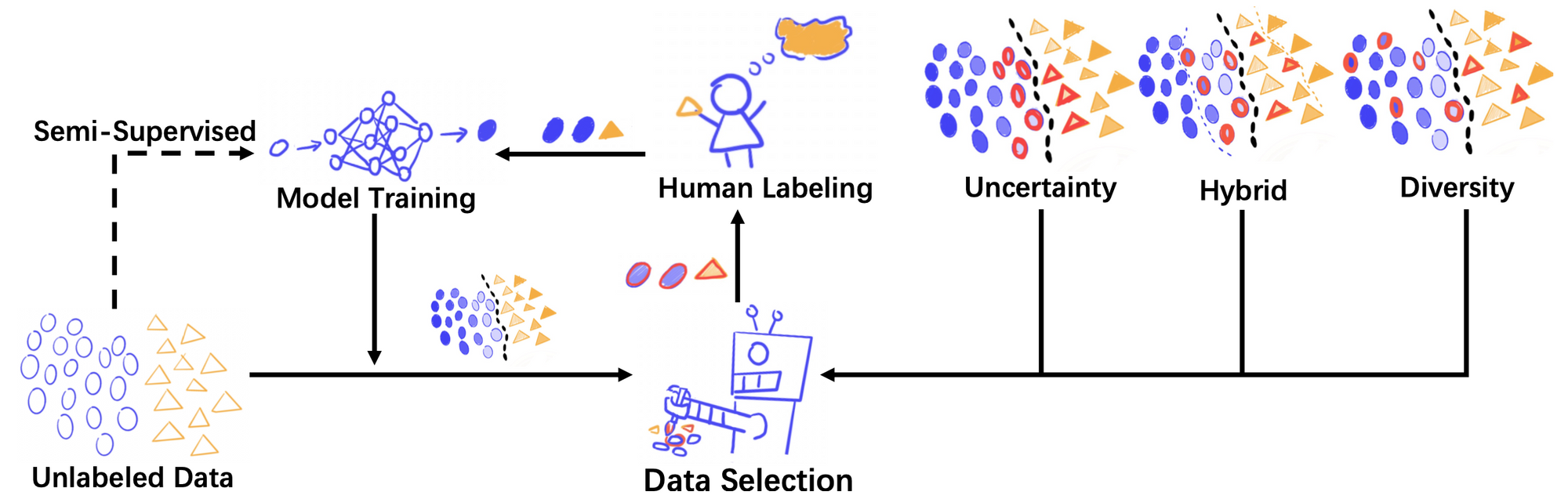
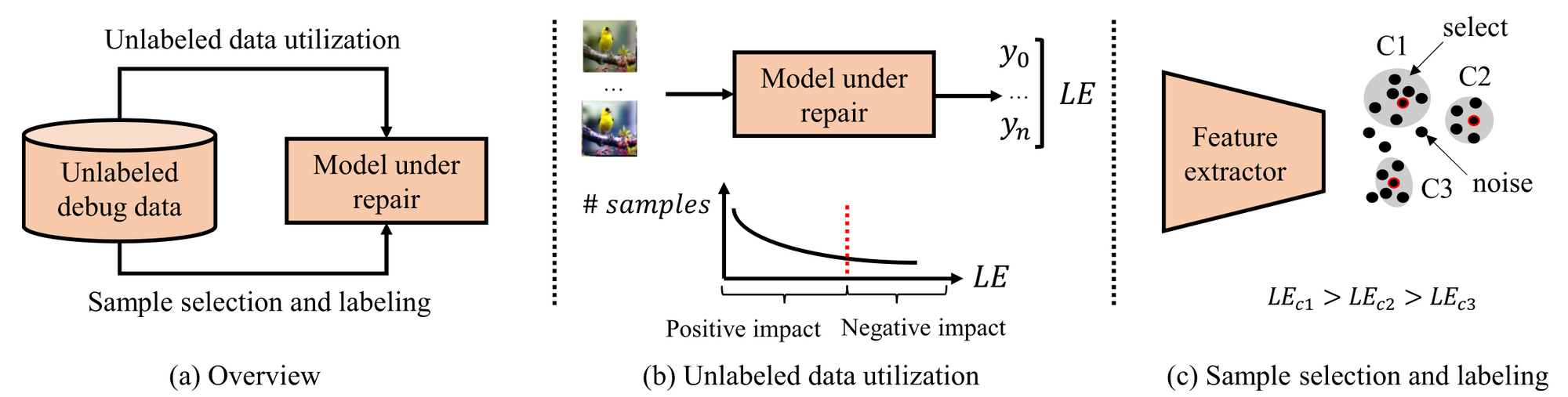
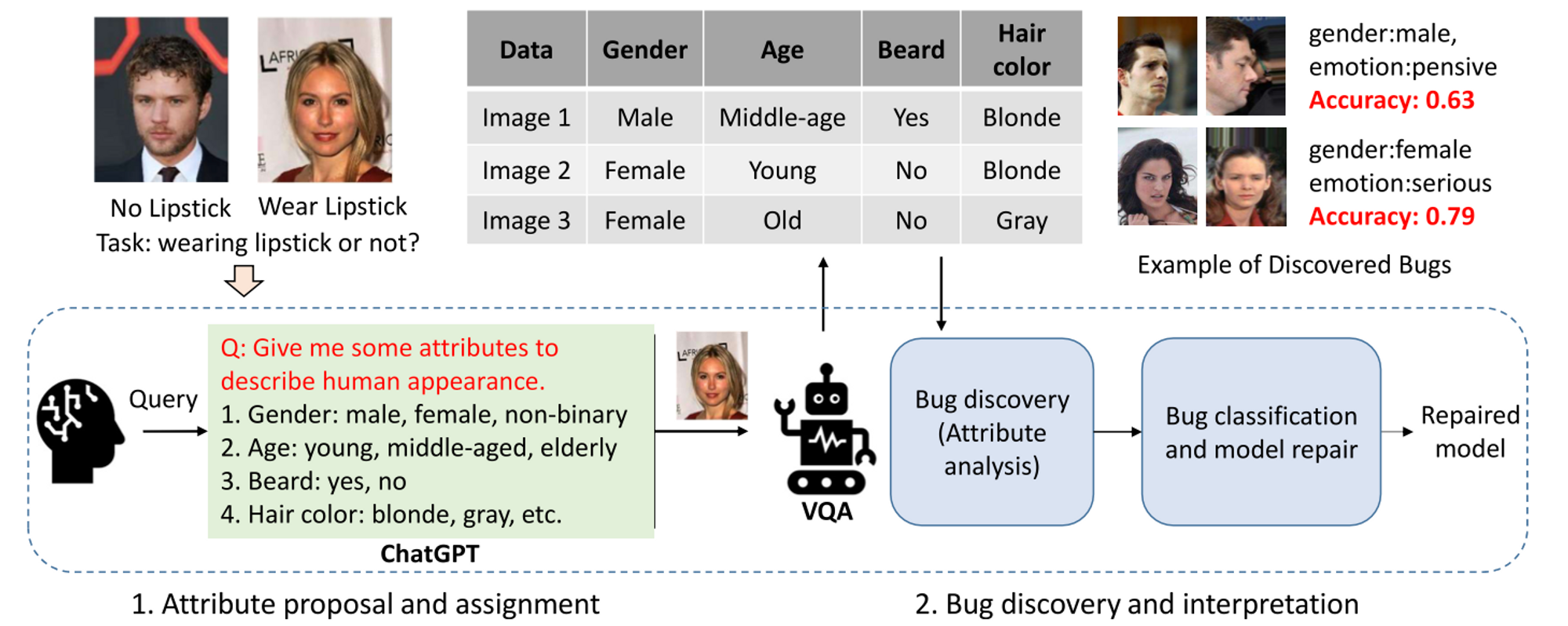
We also devote ourselves to enhancing model performance by pioneering new test and debugging methods. To start, we delve into test input prioritization, a technique designed to pinpoint “high-quality” test instances from a large volume of unlabeled data. Through this selection, we can uncover more model failures with less labeling effort, thereby streamlining the process of identifying and addressing the model’s performance shortfalls. Next, we investigate active learning strategies, which involve choosing a set amount of unlabeled data that, following human annotation and model retraining, could most effectively boost the model’s performance. In addition, we engage in failure discovery and reasoning, a process aimed at identifying visual attributes or specific patterns that are comprehensible to humans and that contribute to model failures. Gaining an understanding of these factors is vital for researchers aiming to improve their models.