HiBug:On Human-Interpretable Model Debug
Machine learning models can frequently produce systematic errors on critical subsets (or slices) of data that share common attributes. Discovering and explaining such model bugs is crucial for reliable model deployment. However, existing bug discovery and interpretation methods usually involve heavy human intervention and annotation, which can be cumbersome and have low bug coverage.
In this paper, we propose HiBug, an automated framework for interpretable model debugging. Our approach utilizes large pre-trained models, such as chatGPT, to suggest human-understandable attributes that are related to the targeted computer vision tasks. By leveraging pre-trained vision-language models, we can efficiently identify common visual attributes of underperforming data slices using human-understandable terms. This enables us to uncover rare cases in the training data, identify spurious correlations in the model, and use the interpretable debug results to select or generate new training data for model improvement. Experimental results demonstrate the efficacy of the HiBug framework.
1. Overview of HiBug
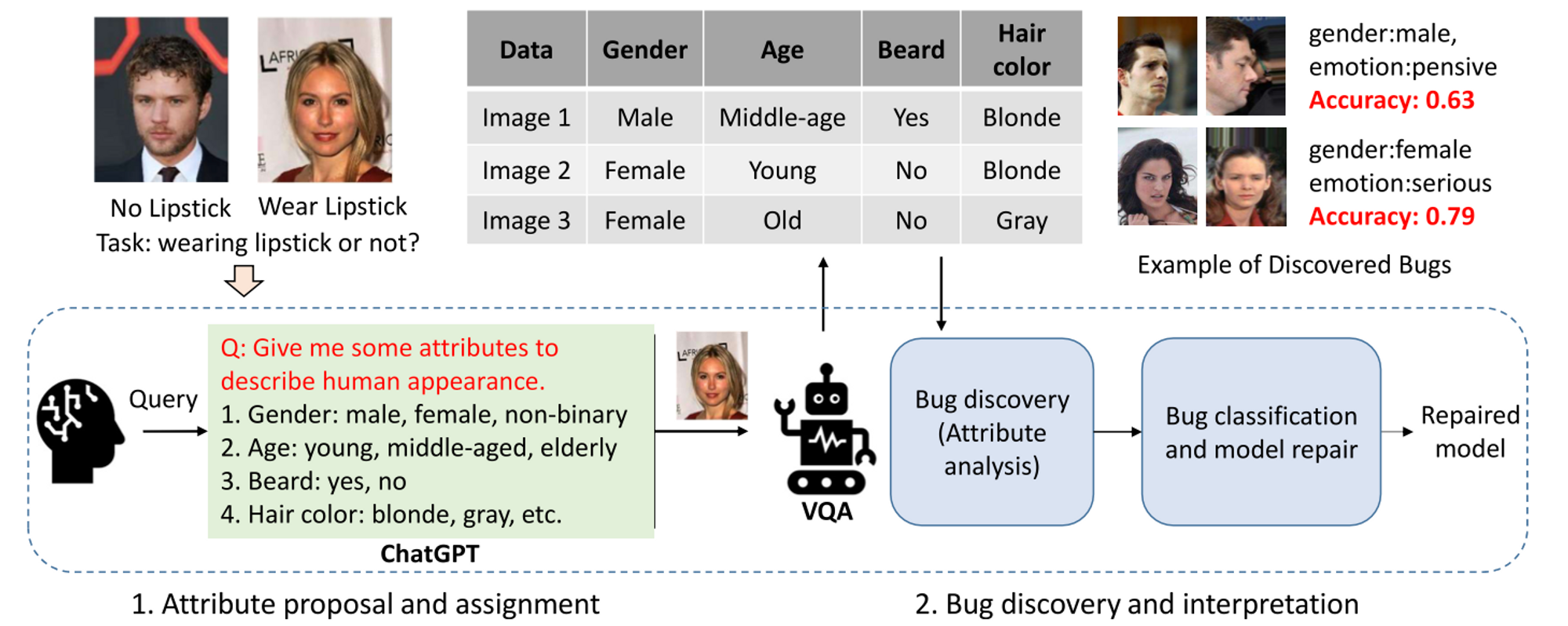
2. Visualization of data slices generated by HiBug

3. Image generated by class name(left) and images generated by prompts from HiBug (right)
