Monocular Human Motion Analysis
Understanding and analysis of human motion is a long-standing task relation to computer vision, computer graphics and robotics. In the past two decades, thanks to the application of motion capture tools, the technologies of motion analysis were developed from manual methods to automatic recoginition, segmentation, and even synthesis. Especially, with the occurrence of deep learning methods, it is possible to analyse human motion based on monocular camera rather the motion capture tools.
In general, research topic and application related to human motion analysis includes (but not limited to):
- Human pose estimation: estimate 2D/3D joint position of human pose and/or reconstruction 3D mesh of human body from video/image.
- Human motion recognition: recognize what kind of motion the person performing in the video.
- Human motion segmentation: segment a complicate human motion into several basic actions.
- Human motion assessment: assess how well the person performed from video.
However, although we can complete several tasks above with a simple trained deep learning model, in most cases, we cannot verify whether the model learned the knowledge of human motion. Typically, models which perform well on benchmarks are easily to fail in-the-wild.
Therefore, our long-term goal of human motion analysis is to help computer learn knowledge of human motion, e.g. how human moves in each action and the limitation on joints freedom. In this way, the computer can utilize the learn knowledge to facilitate the concrete tasks (e.g. the problems above). Actually, it is also possible to help us better understand human motion, and help the development of real-world application like rehabilitation, augmented reality, and computer animation.
The follow of this page lists some of our typical research work in this area for your reference.
Human Pose Estimation
SRNet: Improving Generalization in 3D Human Pose Estimation with a Split-and-Recombine Approach
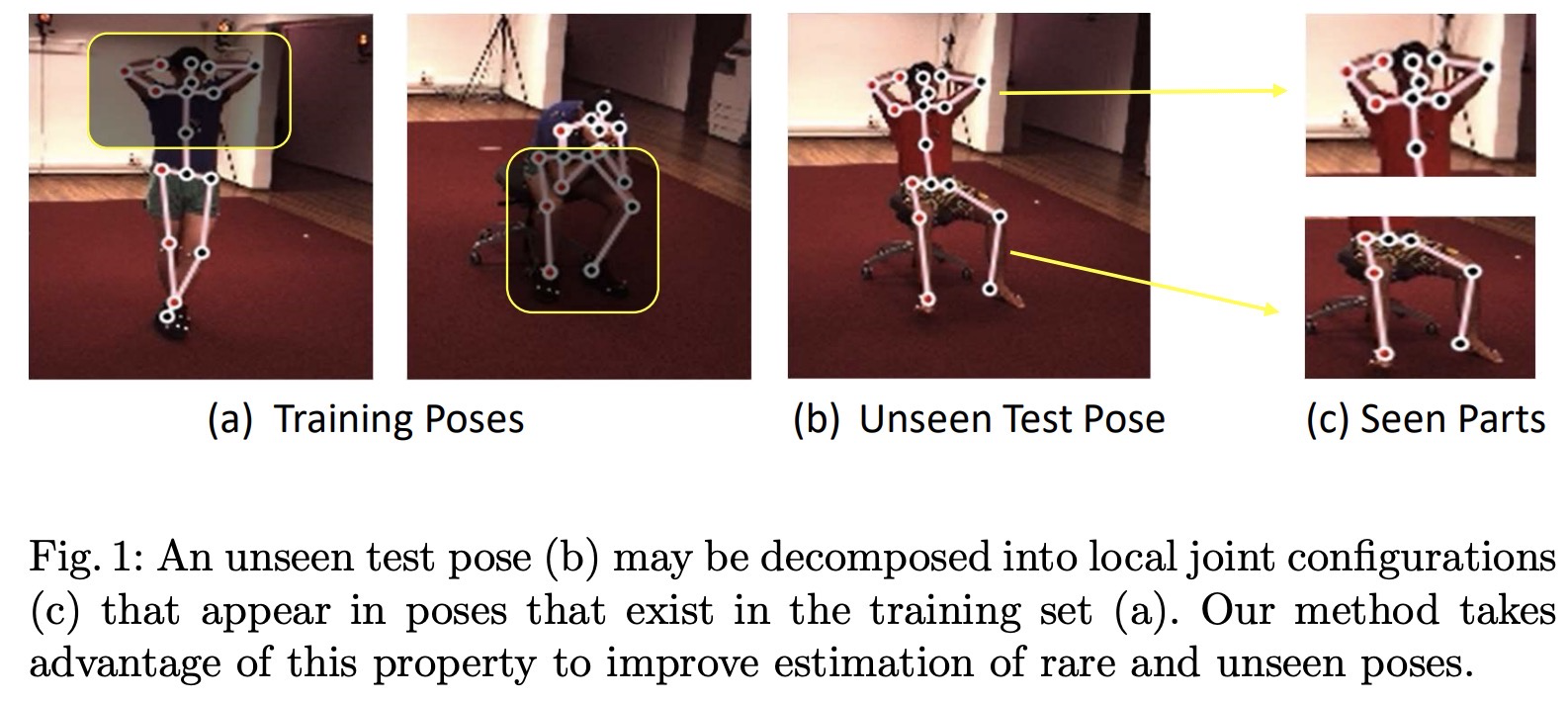
Human pose estimation is a longstanding computer vision problem with numerous applications, including human-computer interaction, augmented reality, and computer animation. For predicting 3D pose, a common approach is to first estimate the positions of keypoints in the 2D image plane, and then lift these keypoints into 3D. It is a challenging task and has drawn lots of attention from academia in recent years. Even though the average performance increases steadily over the years, the prediction errors on some poses are still quite high. We aims to solve this task by improving the generalization ability and tackling hard poses.
Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation

Various deep learning techniques have been proposed to solve the single-view 2D-to-3D pose estimation problem. While the average prediction accuracy has been improved significantly over the years, the performance on hard poses with depth ambiguity, self-occlusion, and complex or rare poses is still far from satisfactory. In thiswork, we target these hard poses and present a novel skeletal GNN learning solution. To be specific, we propose a hop-aware hierarchical channel-squeezing fusion layer to effectively extract relevant information from neighboring nodes while suppressing undesired noises in GNN learning. In addition, we propose a temporal-aware dynamic graph construction procedure that is robust and effective for 3D pose estimation. Experimental results on the Human3.6M dataset show that our solution achieves 10.3% average prediction accuracy improvement and greatly improves on hard poses over state-of-the-art techniques. We further apply the proposed technique on the skeleton-based action recognition task and also achieve state-of-the-art performance.